Service teams – solving the capacity challenge for infrastructure organizations
However, they are also dependent on the infra-tech-guys to do a variety of different deliveries. Installing an application server, configuring a firewall, publishing a new application via citrix farms, managing clusters of servers to increase resilience and redundancy.
Infra organizations are now more than ever counting on the skillsets of their staff to manage these many requests (not to mention all the incidents they also handle). The solution has been to focus on specialization and deepening the skillsets of the individuals to ensure ample supply of the knowledge demanded by customers.
However, it has also meant that we have created a monster of many different bottlenecks. The concept of specialist only works if the level of inflow of work is even and preferably in line with the level of available capacity (available man hours of the specialist).
In reality
In reality the situation is not like this. First off, the specialists are continually interrupted by a wide variety of unplanned work. Incidents of course being the most obvious unplanned work, but equally common are things like having to attend a meeting to discuss the possibilities of setting up a network in a specific way or analyzing a requirement for a new type of application server which may (or may not) become an actual work order. Or having to drop everything you are working on just to support a development team who wants to discuss the potential risks of failing availability due to uncertain workloads and capacity requirements.
Lastly, of course, we have all those situations where whoever needs the infra guy to deliver something is under the impression that this person has nothing else to do and therefore can provide the new database server with the unique configuration today.
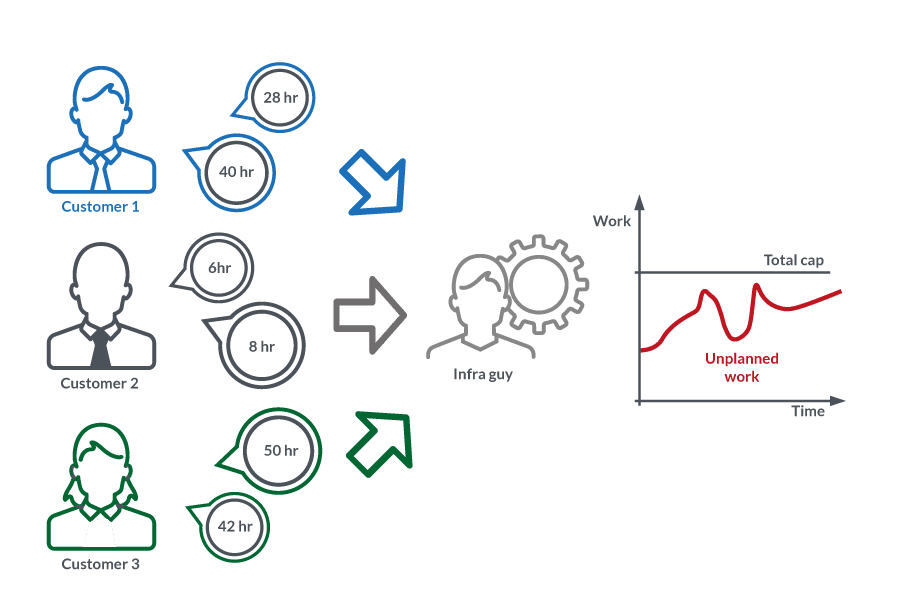
In the drawing above, we can see a fairly common situation. Several customers need the resources of one infra guy. The work is in varied size and uncoordinated and more or less bombards the resource with requests. A resource who is busy managing all sorts of unplanned work. The result in terms of work looks a bit like this.
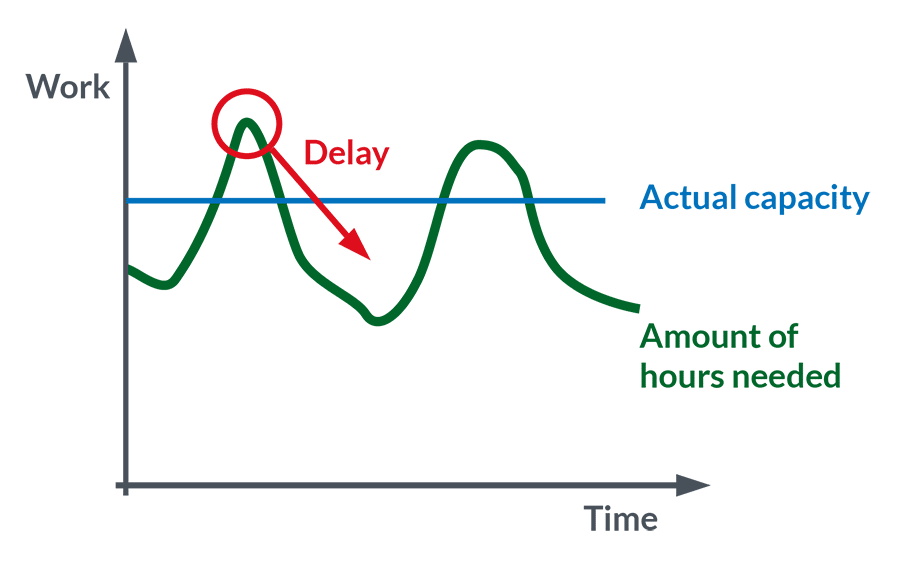
To much work comes in, the specialist is overburdened and therefore delays the work to whenever “I have time for this”. Resulting in longer lead times, frustrated customers and escalated requests resulting in hasty work with the undesired effect of increase in Incidents leading to longer lead times for planned work etc. It is an evil spiral.
What is the solution?
We call it “Service Teams”. What we have to do is design our organization so that we eliminate as many as possible of the skills bottlenecks.
In agile development the concept of the Scrum team consisting only of “developers” has had significant success in evening out workloads, reducing lead times and increasing job as well as customer satisfaction levels.
In the concept of Awesome (ASM-Agile Service Management) we provide concrete practical examples of the benefits of creating “service teams” consisting of several resources from different organizational units and related skillsets.
Using the working models of operations from Agile together with Best practices for IT Service Management we integrate the 1st, 2nd and 3rd line resources into Service Teams.
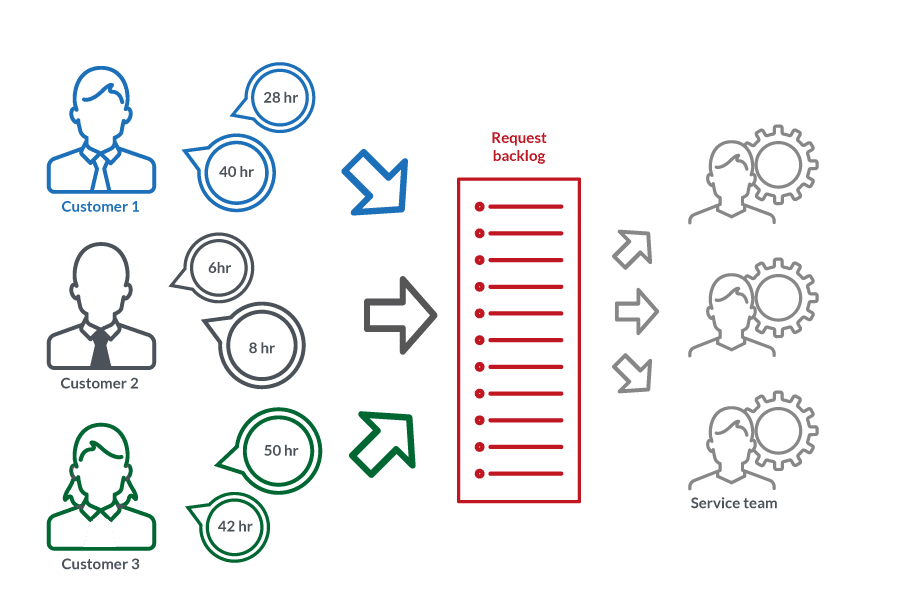
Agile Service Management
MarsLander – learn more how you can practice Agile Service Management!

Kapacitetsplanering inom IT: Så får ni kontroll på leveransen
Service teams – solving the capacity challenge for infrastructure organizations av Torbjörn Dahlström | apr 1, 2018 | AGILE, ITIL/ITSM För CIO:er, IT-chefer och IT-ledare som vill förstå om roadmapen faktiskt går att leverera, innan kapaciteten spricker, ledtiderna ökar och prioriteringarna tappar effekt. Den…

Vad är nytt i ITIL v5?
Service teams – solving the capacity challenge for infrastructure organizations av Torbjörn Dahlström | apr 1, 2018 | AGILE, ITIL/ITSM ITIL v5 – Vad är nytt och vad spelar faktiskt roll? I februari 2026 lanserades ITIL v5. Precis som tidigare uppdateringar bygger den vidare…

IT – en outnyttjad resurs i strävan efter affärsvärde
Service teams – solving the capacity challenge for infrastructure organizations av Torbjörn Dahlström | apr 1, 2018 | AGILE, ITIL/ITSM Trots teknikens avgörande roll i affärsstrategier förblir IT och verksamheten ofta dåligt samordnade. Detta leder till att IT:s fulla potential som strategisk partner inte…
