Grunderna i Change Management enligt ITIL
Change management är en kärnprocess för IT-organisationer och har funnits representerad i ITIL ända sedan starten på 80-talet. Men vad är grunderna i Change management?
Att ha kontroll över vilka förändringar som arbetas på respektive nyligen har satts i produktion är kritiskt för varje IT-organisation. Utan den kontrollen blir det omöjligt att bedöma arbetsbelastning på personal. Svårt att bedöma förväntade ledtider på leveranser. Samt också än svårare att hitta varför plötsliga driftsstörningar uppstår.
I den 4:e versionen av ITIL har processen förfinats ytterligare och har bland annat döpts om till Change Enablement. (Ett kort tag hette den också Change Control). I den här texten har vi valt att behålla det gamla etablerade namnet för enkelhetens skull.
Syftet med processen Change Management enligt ITIL
Några praktiska skäl till change management
- Veta vilka förändringar i miljön som är klara, fortfarande pågår respektive inte är färdiga.
Om du lättare kan se arbetsenheter och hur arbetsflödet ser ut, kan du lättare hitta flaskhalsar och annat som hindrar er effektivitet. - Kunna förstå och bedöma belastning på interna resurser.
Tekniker kan öka sin effektivitet genom att bara jobba med en eller ett fåtal saker i taget. (Läs mer om varför lite längre ned). - Undvika onödiga krockar med andra förändringar av den miljö vi arbetar mot.
Emellanåt finner tekniker att de gör ändringar i miljön samtidigt som andra också är inne och ändrar. Detta kan undvikas genom fungerande change management. - Säkerställa att nödvändig dokumentation uppdateras i samband med förändring.
Dokumentation är alltid en utmaning. Men med en gemensamt etablerad och överenskommen process, kan vi säkerställa att rätt mängd dokumentation utförs. - Undvik onödiga risker genom att ha stringenta metoder för change-arbetet.
Varje förändring av produktionsmiljön är alltid en risk för IT-tjänsternas tillgänglighet och stabilitet. Vi bör då alltså ha effektiva metoder för att undvika att problem uppstår vid produktionssättningar. Såsom test, rollbackplanering innan utrullning, planerad och kommunicerade förändringar i miljön etc. - Förenklad felsökning om det, mot förmodan, visar sig att produktionssättningen/förändringen, inte blev helt lyckad.
Givet att det är någorlunda lätt att hitta vad som ändrats sedan sist så ökar chanserna att snabbt hitta det underliggande feler. - Löpande utveckla och förfina process och tekni. När du väl fått flöden och visualisering på plats är det betydligt lättare att hitta små detaljer att finslipa på. Och nej, de kommer inte att ta slut. Det finns alltid något mer att slipa på.
Definitionen av en Change/Förändring
Vad är då definitionen av en change/förändring? Enligt ITIL 4 så är det varje ändring (new, update, delete) av konfigurationen kring en eller flera komponenter som används för att tillhandahålla en IT-tjänst.
En change kan alltså vara en ändring av en brandväggsregel. Installation av ett nytt OS på server eller dator. Patchning av en programvara. Ny kod i en applikation. Eller egentligen vad som helst som vi betraktar som en ändring av en använd komponent. En komponent i sin tur är alltså någon form av teknikkomponent. Databas, nätverksutrustning, kod, hårdvara etc. Den exakta definitionen av en change kan se lite olika ut mellan organisationer. Men enkel tumregel är att om förändringen kan innebära ökad risk. Och/eller att tjänsten påverkas negativt (dvs slutar fungera enligt önskad eller överenskommen nivå) i samband med förändringen. Då är det en change. Detta innebär alltså att även en kodförändring är att betrakta som en change.
Inte bara produktionssättning
Processen sträcker sig också från det att vi börjar arbeta med förändringen (planeringsfasen) ända till och med produktionssättningen. Tyvärr finner vi alltför ofta att changeprocessen egentligen bara är ”godkänn för produktionssättning”. Vilket alltså är att endast tillämpa en delmäng av change management processen.
Idag har också många organisationer hittat sätt att automatisera mycket av flödet kring produktionssättningar. Speciellt organisationer som anammat DevOps eller mer utvecklade Agile/Scrum-metoder. Och kanske till och med utvecklat någon form av DevOps Pipeline. Detta är helt i linje med ITIL 4s perspektiv på change management. Så länge det finns någon form av dokumentation och versionshantering av dessa ändringar. Även tester ingår i change-flödet, om än som en stödprocess. Även automatiserade tester är också de helt i linje med ITILs definition och målsättning.
Tre typer av Change
Flertalet organisationer har hittat sätt att standardisera och minimera risker med förändringar. Vidare så finns det också ett antal ofta förekommande ”change-ar” som organisationer arbetat på för att förenkla. Och hantera löpande allteftersom de uppstår. Typiskt hittar man på driftsavdelningar ofta standardiserade metoder för att hantera löpande patchar och uppdateringar. Medan lite större förändringar kan behöva lite mer tid, planering, kontroller och uppföljning. Utvecklingsteam har också ofta automatiserat flöden för test, deploy och flyttningar mellan olika miljöer. Utöver det finns det självklart också de där olyckliga tillfällena när vi hittat ett kritiskt säkerhetshål eller har en större incident. Som endast kan lösas med hjälp av en förändring av miljön (givet att vi inte kan göra en rollback bara).
ITILs tre changetyper:
- Standard Change: Denna är känd och har en känd procedur, låg risk och är därför i förväg godkänd. Dvs teknikern behöver inte be om någon form av granskning eller godkännande för att kunna genomföra förändringen. Med fördel kan också dessa förändringar, som ju är återkommande i sin karaktär, scriptas. Så att de kan genomföras än snabbare och med bättre säkerhet.
- Normal Change: Denna kan visserligen vara känd, det kan också vara känd teknik. Men omfattningen på risken med förändringen respektive arbetsinsatsen är av mer omfattande karaktär. Då är bra om någon annan än teknikern faktiskt slänger ett öga på förändringen. Och granskar att man tänkt igenom alla viktiga aspekter av förändringen (mer om detta nedan). Denna change brukar därmed gå igenom någon form av mer formell granskning innan den produktionssätts. Gärna genom någon form av ”peer review”.
- Emergency Change: Egentligen kan en emergency change vara vilken som av de ovanstående typerna. Men den har till skillnad från de övriga en tidsfrist som är extremt kort. Därmed kan vi tolerera en högre grad av flexibilitet kring dokumentation etc. Vilket kan göras i efterhand. Emergency change-ar skall endast vara triggade av större driftsstörningar eller identifierade större säkerhetshål. Inte som det ibland blir. Ett sätt att försöka gå runt CAB:en. Akuta förändringar ska helst hållas till ett minimum, gärna noll per år.
Change authority – eller CAB som det hette i ITIL v3
Idag har de allra flesta organisationer någon form av formell funktion för att granska och schemalägga förändringar till produktionsmiljön. Vissa har det till och med för utvecklings- och eller stage-miljö. Det är dock tveksamt om det är en rekommenderad väg att gå avseende utvecklingsmiljöer. I ITIL v3 rekommenderade man att skapa en definierad grupp som godkände förändringar kallad CAB (Change Advisory Board). Vilket man nu ändrat genom att istället referera till ”Change authority” som alltså kan vara lite mer flytande.
Change authority
Hur definieras en Change authority? ITILs definition av detta är ”the nominated authority with mandate to approve changes”. Det här kan låta lite högtravande och många organisationer har kanske fastnat på ordet Authority. För det första så behöver Change Authority:n på inget sätt vara med och godkänna varje förändring. Dels enligt change-typerna ovan och dels för att det helt enkelt inte är effektivt. För det andra så betyder definitionen heller inte att det bara finns en Change Authority (framöver kallar vi den för CA för enkelhetens skull). Som ska kontrollera alla förändringar som görs. Tvärtom kan en organisation ha så många CA:s den själv vill. Slutligen så ska CA:n bestå av folk med kompetens att förstå problemställningen. Dvs det ska vara tekniker som kan bedöma den tekniska risken/förutsättningen. Inte nödvändigtvis chefer eller andra som potentiellt inte har den nödvändiga tekniska insikten.
Ofta är det dock någon form av formell linjeauktoritet med i gruppen (CA:n) men det är inte något som ITIL specifikt förordar. Tvärtom så definierar ITIL 4 tydligt att ”peer reviewing” snarare är en toppmarkör på effektiv hantering snarare än större formella diskussionsforum. Speciellt i organisationer med ”high change velocity” som man återfinner i effektiva agila team.
Emergency change authority
Kopplat till CA brukar det också finnas någon form av Emergency-CA eller liknande. Det är en funktion (en eller flera individer i organisationen) som vid behov av en akut förändring har mandat att godkänna eller avslå. Dessa individer kan vara medlemmar av den vanliga CA:n eller ha en helt egen definierad roll. Ibland kallas den rollen ”Critical Situation Manager”, ”Incident Manager”, ”Shift captain” eller andra liknande (påhittiga) namn.
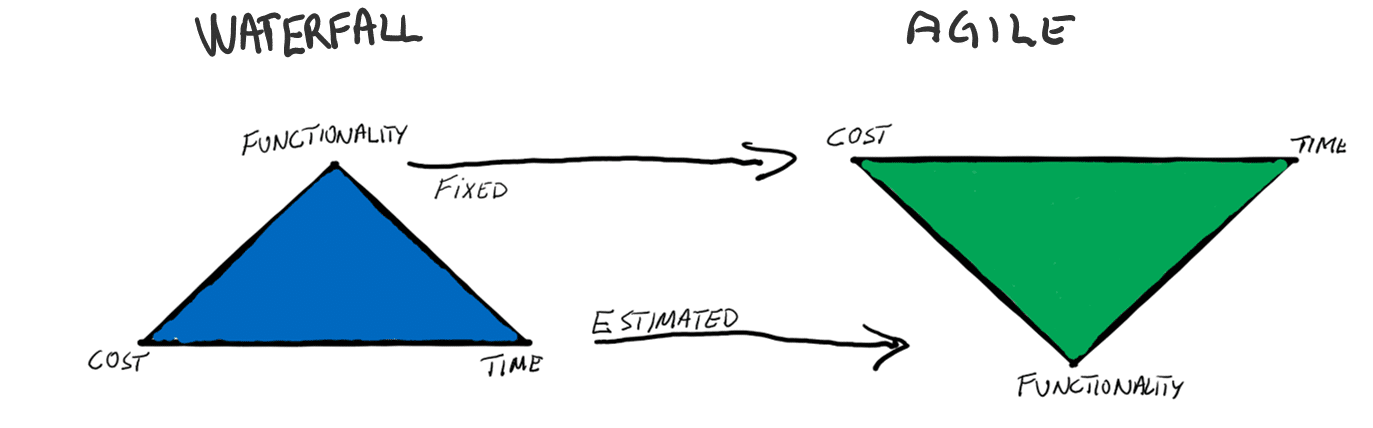
Vi jobbar inte enligt vattenfalls-ITIL, vi är agila!?
På vilket sätt hänger Change management ihop med agil utveckling och agila team? Intressant nog så är det i den agila cykeln väldigt tydligt definierat hur man samlar förändringsönskemål i en backlogg. För att sedan, på ett möjligen informellt men ändå mycket strukturerat sätt, besluta om exakt vilka förändringar som man avser att göra inom ramen för en Sprint.
Detta är i praktiken att till fullo följa ITIL-processen om än med andra ord. (En change heter till exempel inte change utan user story eller något liknande). Ett product team meeting där Product owner tillika utvecklarna träffas. För att gemensamt diskutera fram vilka prioriteringar man har för en given sprint är den agila motsvarigheten till ett CA-möte. Därmed finns det egentligen ingen konflikt mellan processerna, möjligen finns det dock en viss språkförbistring
Hur och varför ska man dokumentera en Change/Förändring?
Det finns egentligen inga exakta regler kring detta men ett par saker är bra att tänka på:
- Vi vill gärna göra andra medvetna om vad vi jobbar med så att vi inte råkar introducera några onödiga krockar.
- Någonstans måste det ändå finnas någon form av minimum av information som definierar hur miljön ser ut. Alltså behöver vi dokumentera detta någonstans någorlunda lättillgängligt.
- Arbete som inte är synligt gör det svårt att bedöma arbetsbelastning respektive förväntade leveranstider.
- Om det uppstår bekymmer efter en produktionssättning så kan vi väsentligen korta ner felsökningstiden om vi på ett enkelt sätt kan se vad som nyligen har förändrats.
- Keep it simple. På tok för många organisationer skapar på tok för komplexa lösningar kring change-process och dokumentation. Omöjliga workflows, oändliga mängder fält som ska fyllas i (och vars data aldrig följs upp). Krångliga steg i processen med inbyggda väntetider som förlänger ledtider etc. Undvik allt detta som pesten.
Tips
Finner ni det svårt att komma igång med processen i er organisation? Ser ni att personalen inte följer processen för change management fundera då över hur du kan förenkla den. Genom att förenkla kraven på dokumentation, estimering, tidssättning etc så är det lättare att få acceptans för arbetssättet. Att visualisera arbetet på en kanbantavla eller liknande förenklar också. På ett enkelt sätt kan man då dokumentera förändringar så att informationen blir lättillgänglig för de som behöver den. Tillsammans kan ni då hitta bra, enkla och tillgängliga lösningar.
Tillit, inte kontroll
Försök heller inte sälja in processen med illa valda motiveringar. “Vi kan inte lita på att ni tekniker inte ska introducera fel och brister i vår miljö, så därför gör vi det så omständligt som möjligt. Genom byråkratiska processer, tunga beslutsprocesser, omfattande dokumentation” etc. Då har vi skapat motstånd och inte acceptans. Börja hellre då en dialog om hur vi ska kunna säkerställa att inte unika individer blir helt dränkta i för mycket arbete. Samt hur vi genom bättre kontroll på change-processen kan förstå hur mycket jobb vi har att gjort och kvar att göra.
Hur ser change-processen ut?
Det finns en del goda råd och tips att hämta från ITIL på hur en generisk changeprocess kan se ut. Det viktiga dock är att man börjar enkelt och över tid när behov infinner sig utökar. I korta drag kan man säga att processen består av följande 4 steg.

Det finns en del goda råd och tips att hämta från ITIL på hur en generisk changeprocess kan se ut. Det viktiga dock är att man börjar enkelt och över tid när behov infinner sig utökar. I korta drag kan man säga att processen består av följande 4 steg.
Observera att change-en börjar alltså redan när vi får ett behov om att ändra något. Den börjar inte när vi jobbat med det under någon månad eller så och nu önskar gå till produktion . Vidare så förordar den att vi ska kontrollera att det vi önskar ändra på kommer att fungera även efter förändringen. Det vanligaste är faktiskt att de komponenter vi ändrar på fungerar utmärkt även efter ändringen. Dessvärre finns det ofta andra komponenter som är beroende av den nyförändrade komponenten och som efter förändringen kanske inte riktigt fungerar som de ska. Detta är då en change-skapad incident.
Ingen change utan Rollback!
Varje förändring som vi implementerar i produktionsmiljön ska helst kunna återkallas om den visar sig skapa bekymmer. Detta kallas för Rollback. Livet skulle vara enkelt om vi kunde använda detta som en regel men det finns dock tillfällen då förändringen inte kan återkallas. Till exempel om vi skapat nya data som skulle försvinna. Eller den komponent vi ändrat på går helt enkelt inte att återställa.
Detta betyder dock inte att rollbackplanering blir dispositiv. Istället så ska vi göra den rollbackplanering som går. Med hjälp av de verktyg inom tex DevOps kan vi automatisera delar av eller hela rollbacks. Till och med till den nivån att larmsystem som upptäcker fel efter förändring också automatiskt kan genomföra återkallande till senast kända fungerande konfiguration. Vvilket ju också är varför det är så viktigt att dokumentera och versionshantera allt.
Rollback som standard
Rollback skall alltså planeras för. Om det inte bedöms som möjligt så skall detta vara med i risk-kalkylen som görs innan produktionssättning. Man måste också definiera en ”point of no return”. Dvs hur länge kan vi befinna oss i den nya förändrade miljön och tryggt rulla tillbaka om något fel uppstår eller när har vi gått förbi denna osynliga gräns. Det kan handla om en definierad tidsrymd, datamängd eller annat som påverkar. Men se till att ha tänkt igenom dessa alternativ innan ni gör er förändring.
Change och Incidenter
Det är väl inte alla som vill erkänna att en förändring de gjort skapat bekymmer i produktionsmiljön efteråt. Speciellt inte om man inte lever i en ”blame free culture”. Men den bistra sanningen är att de allra flesta incidenter som uppstår gör det på grund av att något har ändrats i miljön. Väldigt få saker slutar fungera av sig själva. Vidare så är det lätt hänt att olika change-ar krockar med varandra. Alldeles för vanligt i organisationer där den ena handen inte vet vad den andra gör. Det är alltså rimligt att tro att en change kan resultera i en incident. För att råda bot på detta och minimera risken så finns det ett par saker man kan göra.
6 tips för färre incidenter
- Undvik stora förändringar, dela upp dem i många små. Detta är också helt i linje med hur vi jobbar inom agil systemutveckling. Om du lättare kan se arbetsenheter och hur arbetsflödet ser ut, kan du lättare hitta flaskhalsar och annat som hindrar er effektivitet.
- Se till att ha koll på vilka förändringar som jobbas på så att du på ett enkelt sätt kan kommunicera det till resten av organisationen. Då kan du också undvika onödiga krockar. Genom att bara jobba med en sak i taget blir du mer effektiv. Läs mer om varför lite längre ned.
- Testa ordentligt. Det ska också göras så tidigt som möjligt i processen, inte bara på slutet. Det kanske finns några steg i ert flöde som saknas? Eller några som egentligen är onödiga och borde tas bort?
- Sköt din dokumentation över miljön så du vet vad du förändrar. När du väl fått flöden och visualisering på plats är det betydligt lättare att hitta små detaljer att finslipa på. Och nej, de kommer inte att ta slut. Det finns alltid något mer att slipa på.
- Manuella förändringar skapar lättare fel. Sedan länge jobbar vi med förändringar av klienter med stöd av distributions- och ”deploy-” verktyg. Samma ska gälla för servrar, nätverksutrustning etc. Gör vi fel med automatiserad deploy så vet vi åtminstone alltid exakt vilket fel vi gjort.
- Betrakta inte en incident skapad av en change som endast negativ. Det finns tvärtom väldigt många goda lärdomar vi kan göra från dessa tillfällen. Om vi bara tar oss tid att reflektera och lära oss. Man kan lära sig oerhört mycket så länge man inte är upptagen med att förklara varför man inte har fel.

Hur mäter vi changeprocessen?
Mätning, målstyrning och KPI:er är naturligtvis också ett viktigt område för Change Management. Vi tror att det här, precis som innan alla områden, är viktigt att man börjar i små steg. För att sedan i iterationer utvecklar lämpliga sätt att mäta och utvärdera changerpocessen. ITIL-publikationerna redovisar också flera olika nyckeltal som flera av dem är bra men kanske inte alla ska anammas från första början. Nedan listar vi vad vi tycker är några bra värden att utgå ifrån och sedan utveckla allteftersom:
- Antal nya och levererade change-ar per period (för att se om vi håller tempot mot efterfrågan)
- Inkomna men ännu hanterade ärenden. Change backlog (dock är detta i huvudsak relevant för en operationsfunktion)
- Andel Change som inte fungerar enligt plan från början (trendlinje). Change fail rate
- Ledtid (Leadtime) för Change från ax till limpa. Alltså inte bara tid för godkänna till deploy.
- Workload / resource som hanterar Change
- Change WIP. Dvs antalet samtidigt pågående changear där målet är att ha så få som möjligt.
Avslutningsvis
Det går inte att överskatta värdet av en väl fungerande changeprocess. Att hantera förändringar på ett säkert men snabb sätt är kritiskt i en värld där kraven på nya funktioner och tjänster hela tiden ökar. Vi återkommer dock alltid till att det är en process där vi bäst utvecklar den i många små iterationer. Vi tror också att det är bäst att detta görs av teknikerna som ska jobba i processen snarare än att ha en central processfunktion som skriver instruktioner till andra. Sådant förhållningssät tenderar ofta att sluta med delvis accepterade processer. Haltande införande och i värsta fall också en hel del missnöje internt i organisationen. Över krångliga verktyg, byråkratiska processer och chefer som övervakar vårt arbete.
Vill du analysera ditt change-flöde?
Hämta vår SIPOC-guide, så kan du enkelare strukturera och visualisera hur ditt change-flöde ser ut.

Kapacitetsplanering inom IT: Så får ni kontroll på leveransen
Grunderna i Change Management enligt ITIL av Torbjörn Dahlström | jul 29, 2019 | ITIL/ITSM För CIO:er, IT-chefer och IT-ledare som vill förstå om roadmapen faktiskt går att leverera, innan kapaciteten spricker, ledtiderna ökar och prioriteringarna tappar effekt. Den här sidan riktar sig till…

Vad är nytt i ITIL v5?
Grunderna i Change Management enligt ITIL av Torbjörn Dahlström | jul 29, 2019 | ITIL/ITSM ITIL v5 – Vad är nytt och vad spelar faktiskt roll? I februari 2026 lanserades ITIL v5. Precis som tidigare uppdateringar bygger den vidare på tidigare versioner snarare än…

Kundcase Restaurangkedjan - bättre kontroll på leveranser
Onbird hjälper restaurangkedjan få bättre kontroll på och kortare ledtider i IT-leveranser
