Detta är DevOps, en grundläggande sammanfattning
Bakgrund och historik
Konceptet DevOps sägs ha sin tillkomst runt 2008 i samband med en konferens som hölls på ämnet agil utveckling och Lean som verksamhetsstrategi för IT-organisationer. Termen är förståeligt nog en sammanslagning av Development och Operations. Eller på svenska: Utveckling och Drift.
DevOps tar sitt avstamp i erkännande av både Lean– och Agile, men kombinerar och utvecklar dem till en gemensam, modern samling av metoder och praktiker som fångar det framgångsrika ur båda dessa tankesätt.
Många som har arbetat Agilt ser över tid att man fortfarande har utmaningar med den totala leveransen, även om teamen levererar snabbare och med högre kvalitet.
DevOps är en bekräftelse på att utveckling och drift måste samarbeta under gemensamma principer. Principer som syftar till att säkerställa att leveransen från krav till fungerande produktion ska ske på snabbast möjligast sätt, till bästa tänkbara kvalitet, end-to-end.
Varför DevOps?
Framkomsten av konceptet var en strävan efter att komma ännu närmare en mer total leverans av IT än vad som ofta är fallet i organisationer där Utveckling och Drift är separata funktioner (som helst har så lite som möjligt med varandra att göra)
De flesta organisationer strävar efter olika former av effektivitet och kanske framför allt kostnadseffektivitet genom att dela upp funktionerna. Argumentet är ganska enkelt – genom att specialisera sig på ett område och skapa standarder för det området blir det kostnadseffektivt, säkert och lätthanterligt.
Men dessvärre kan detta ofta innebära att det istället skapar bekymmer för den andra funktionen. T.ex., väljer vi att på driftsidan standardisera till en viss typ av operativsystem och plattform. Vilket vi sedan önskar att utvecklare ska förhålla sig till. Men det skapar inlåsning för utvecklarna. Men också ofta, som ett oönskat resultat, situationer där det är oklart vem som ansvarar för vad. Till exempel i samband med att incidenter uppstår.
Där utvecklingssidan (gärna påhejade av affären) vill göra så många förändringar som möjligt. Vill driften hålla hög stabilitet och därmed minska antalet förändringar. Hög THROUGHPUT ställs mot STABILITET.


Uppdelningen av Utveckling och Drift skapar många problem:
- Konflikter mellan funktionerna utveckling och drift.
- Ovilja eller oförmåga att tala gemensamt språk.
- Användande av icke gemensamma verktyg.
- Funktionerna jobbar inte i en gemensam total leverans till kunden där inte bara ny fiffig funktionalitet snabbt produktionssätts utan även den löpande driften fungerar smärtfritt.
- Hantering av test sker i silos utan kontroll på hela leveransinnehållet.
- Incidenthantering fastnar mellan funktioner som gärna skyller felen på varandra snarare än arbetar tillsammans för att lösa både incident och problem.
Alltihop ovan får den olyckliga effekten att leverans till kund blir lidande både vad gäller time-to-market såväl som tillförlitlighet i termer av kapacitet, tillgänglighet och säkerhet. Låt oss inte heller ens prata om situationen där vi måste göra en större återställning i samband med en katastrof eller liknande.
DevOps grundprinciper – The Three Ways
The First Way Of DevOps
The outcomes of putting the First Way into practice include never passing a known defect to downstream work centers, never allowing local optimization to create global degradation, always seeking to increase flow.

Med detta tar man vad som ibland kallas för ett systemperspektiv eller helhetsflöde. Det innebär att istället för att titta på detta flöde silo för silo, så strävar man efter att skapa ett end-to-end-flöde där de som arbetar i flödet bär med sig sin produkt hela vägen till slutmålet och inte till något delmål på vägen. Vidare innebär detta att man aldrig får arbeta på ett sådant sätt att det skapar problem för nästa instans på vägen till slutmålet.
The Second Way Of DevOps
The outcomes of the Second Way include understanding and responding to all customers, internal and external, shortening and amplifying all feedback loops, and embedding knowledge where we need it.
The Third Way Of DevOps
The third way is about creating a culture that fosters two things: continual experimentation, which requires taking risks and learning from success and failure; and understanding that repetition and practice is the prerequisite to mastery.
Här menas att vi måste fostra en kultur där ständiga experiment i förbättrade metoder och verktyg hela tiden görs. I syfte att öka flödet med bibehållen och förbättrad kvalitet på slutprodukten. För att nå dit måste vi våga pröva nya saker. Ifrågasätta gamla sanningar, utveckla Kaizenbaserade problemlösningsförmågor och acceptera misslyckanden för vad de egentligen är. En möjlighet att lära sig och förbättras. Den andra satsen fokuserar i sin tur på att genom ständig övning, träning och repetition utveckla perfekta metoder för vårt arbete.
Vad DevOps INTE är
Vi har flera gånger hört våra kunder och andra organisationer säga att de behöver anställa eller anlita en DevOps-person. Idén är ganska enkel. En roll som syftar till att få Dev och Ops att börja arbeta bättre tillsammans. Tänkt att fungera som själva bryggan mellan Dev och Ops. Dessvärre är detta inte en särskilt genomtänkt idé, och den är heller inte alls i linje med vad en övergång till DevOps faktiskt betyder för en organisation.
För att tydliggöra det här kan vi gå igenom vad Devops inte är:
- Det är inte en organisationsform. DevOps kan visserligen betyda att vi väljer att omorganisera oss, men det är inte att slänga in fem utvecklare och två driftare i en grupp och kalla dem DevOps.
- Det är inte ett ramverk eller en Best Practice som till exempel Scrum, ITIL eller Cobit. Däremot är det ett paraplykoncept som referera till allt som vi gör för att skapa smidigare interaktion mellan affär, utveckling och drift. Och därmed snabbare totalleveranser till kund. Med bibehållen eller förbättrad tillförlitlighet i driften.
- Det är inte att göra sig av med driftfunktionen genom att lägga allt i molnet. Visserligen kan vi säkert uppnå många önskade positiva effekter i molnet. Molnet är dock varken målet eller medlet. Intressant nog så var upphovsmännen till DevOps inte utvecklare utan traditionella “Sysmans” (system managers, eller driftspersonal).
- Det är inte en utvecklingsmetodik. DevOps beskriver inga specifika regler, råd, processer eller metoder för enkom systemutveckling utan har ett bredare perspektiv än så.
- Det är inte en metod för automatisering. Visserligen kommer ett DevOps-initiativ med all säkerhet rendera i fokus på automatisering. Ett antal processer, steg och aktiviteter kan komma att automatiseras. Men då enkom i syfte att uppnå ett snabbare flöde från idé till produktion. Med både drifts- och utvecklingsgruppens goda minne och deltagande i automatiseringen.
- DevOps är inte bara till för Utveckling. Tvärtom, så står DevOps med varsitt ben väl förankrat i både utveckling och drift. DevOpsprinciperna säger egentligen att man inte får låta den ena sidan skapa bekymmer för den andra. Utveckling och stabil drift måste alltså vara det gemensamma målet för hela organisationen.
I första hand handlar DevOps om att sträva mot “flow” eller flöde som vi säger på svenska.
Detta innebär att vi som organisation strävar mot att skapa ett enhetligt flöde. Ett flöde som inkluderar hela leveransen från kundkrav till realiserad och löpande hanterad tjänsteleverans. Det här betyder alltså att från det att kunden önskar ny funktionalitet, eller kapacitet, så ska vi som organisation försöka säkerställa att kravet kan så att säga rinna rakt igenom organisationen. Utan att stoppas på sin väg mot produktionssättning till löpande leverans. Så att kunden därmed kan realisera vinsten av den investering de gjort.
I praktiska termer så kommer vi alltså behöva att utveckla kod. Testa kod. Produktionssätta kod och sedan drifta denna kod med minsta möjliga felfrekvens på vägen. Helst ska koden flöda i ett stycke genom hela organisationen.
Att införa DevOps
Som stöd för införande av DevOps kan vi använda DASA Framework. DASA står för DevOps Agile Skills Association och är en icke-vinstdrivande organisation. DASA verkar för att sprida DevOps. Utveckla ”Best Practices” kring DevOps. Samt skapa en kompetensbank med tillhörande möjligheter till studier och kompetensutveckling. För hågade även potentiellt också certifiering.
Inom ramen för DASA framework ingår DevOps Integration Model. En modell som på ett bra sätt definierar huvudområden för en organisation att utveckla baserat på DevOps. I min analys har jag förenklat denna modell och försökt att bryta ner och förklara vad jag tycker att varje område innebär och hur det ska hanteras.
Modellen utgörs av fem huvudsakliga områden: Performance, Flow, Automation, Organization samt Behavior & Attitude.

Utvecklingen av respektive område kan göras oberoende av övriga andra områden. Ett holistiskt perspektiv är doch att rekommendera, då områdena är samverkande. Vidare är det också viktigt att frigöra möjligheten till utveckling genom den personal vi har och deras kompetens. Snarare än att utgå från ett perspektiv där Management har alla svar och personalen bara frågor. Man bör dock undvika att hamna i en situation där graden av utveckling inom ett eller flera områden markant avviker från något annat. Tänk hellre i termer av många små iterationer av förbättringar tvärs över dessa områden.
Här är några råd i arbetet med att utveckla nya förmågor i er organisation utifrån våra erfarenheter kring respektive område.
Performance
– Mätbar förmåga att leverera komponenter till kund
- Definiera hela värdeströmmen som ett enhetligt flöde, inte som en mängd överlämningar mellan olika funktioner. Här kan vi utgå från Lean ITs principer för “value stream mapping”, “flow” och “units of work/single piece flow”. Sättet vi gör detta är genom att först definiera ett scope för flödet (tex med SIPOC-modellen). För att sedan definiera vilka steg och aktiviteter som vi faktiskt utför inom flödet. Här särskiljer vi på aktiviteter som ur ett kundperspektiv är värdeskapande och de som inte är det. Ett exempel på value stream mapping för en IT-organisation, skulle i praktiska termer kunna vara aktiviteter för ett nytt kundkrav såsom kravfångst, prioritering, utveckling, test, produktionssättning eller något åt det hållet.
- Utifrån detta värdeflöde kan vi sedan försöka identifiera överlämningar mellan funktioner. Begränsningar i arkitektur och potentiella flaskhalsar till flödet. Som på olika sätt hindrar enheten vi utvecklar att gå direkt från idé till produktion.
- Flödet ska också utgå ifrån ett “one-piece-flow”-perspektiv. Det betyder att vi istället för att gruppera en mängd olika nya krav i en release. Så låter vi varje krav rinna genom hela kedjan ut i en produktionssättning för endast det enstaka nya kundkravet. Tex en ny “blå knapp”.

Flow
– Ett flöde av aktiviteter som sker sekventiellt utan väntetid mellan stegen. Som initieras av att kunden drar (”pull”) in nya krav i leveransprocessen.
Mät på leveransen genom hela kedjan och kvaliteten på slutresultatet.
- Därmed beskriver vi en förändring som går i ett stycke från krav till produktion. Inte som en mängd grupperade sprint items eller förändringar som kommer ut i gemensamma, större releaser. Vidare uppstår förändringen redan vid kundkravet och är inte bara en fråga om aktiviteten “produktionssättning”. Varje förändring går alltså genom de av oss definierade aktiviteterna/flödet till kund.
- Utveckla arkitektur och plattform för att möjliggöra detta. Vi skall alltså sträva efter att ha en arkitektur som har begränsad komplexitet. Där det är lätt att automatiserat produktionssätta komponenter. Självklart en övning som kan ta både tid och ha många komplexa tekniska problem att lösa på vägen. I praktiken pratar vi helt enkelt om att städa upp i våra miljöer, bygga bort ostrukturerade integrationer och följa uppsatta arkitekturprinciper.
- Jobba med test, stage och produktionsmiljöer som är kopior av varandra. Använd en staging-miljö som master för produktionsmiljön för att kunna hantera säkra produktionssättningar. Där inget får gå till produktion utan att först ha “körts i staging”. Virtualisering ger här gott stöd och goda förutsättningar för detta.
- Mät sedan på tid för leveransy. Antal fel i produktionssatta komponenter etc. Vi kan med säkerhet ut gå från att de allra flesta fel som uppstår i vår leverans har att göra med att någon varit inne och ändrat i miljön.
Organisation
– Roller, ansvar och arbetsbeskrivningar utifrån ett kundfokuserat perspektiv.
Organisera i självstyrande team som har ansvar för den givna tjänstens hela livscykel, inte bara en del. Teamet bör kunna ta ansvar för hela tjänsteleveransen. Därmed inte bara ha mandatet utan även kompetensen som krävs för att stödja varandras arbetsuppgifter.
- Sammansättningen av ett team måste alltså inkludera inte bara utvecklingskompetens utan även drift och underhåll. Teamet har ansvar för sin produkt även efter release!
- Använd 3:1-modellen från Lean. D.v.s. att varje person i teamet kan utföra tre olika uppgifter och att varje uppgift kan utföras av tre olika personer. För att identifiera vilka kompetenser som måste delas/finns representerade på flera platser. Isyfte att undvika kompetensmässiga flaskhalsar. En kompetenskartläggning och en “skills matrix” kan ge gott stöd för att matcha tillgång och efterfrågan av kompetens.
- Utgå ifrån att det finns personella flaskhalsar som vi ständigt måste eliminera. Dels genom att sprida kompetens och dels genom att automatisera det som idag ofta hanteras manuellt.
- Utveckla förmågor hos driftsfunktion/teammedlemmar att skriva kod för att driva automatisering av sina komponenter.
Behavior & Attitude
– Kulturella drivare och principer för hur vi leder vår verksamhet. Som vi vill ska vara manifesterade i organisationen från Management och vidare i organisationen.
Utveckla beteenden och ett fokus i teamen som strävar mot kvalitet, lärande och ständig förbättring.
- Tolerera inte medioker leverans. Låt inte lokal optimering i en funktion skapa bekymmer eller hinder för det övergripande värdeflödet som mappats ut.
- Försök inte att bygga perfekta lösningar från början. Utan som Bill Gates brukade säga: “do not build perfect software, make it good enough, then deploy and learn and improve”. Samma sak gäller här. Gärna i korta iterationer och ett agilt förhållningssätt.
- Var heller inte rädd för att pröva nya saker givet att detta låter sig göras ganska enkelt och med små medel. Undvika stora komplexa lösningar men pröva gärna många små. Här brukar det löna sig att försöka tänka utanför lådan!
- Jobba i korta iterationer där det går snabbt att åtgärda fel som upptäcks. Snarare än att behöva vänta flera månader på nästa release. Använd korta sprintar enligt Agil metodik.
- Avsätt tid för lärande, reflektion och framförallt förbättringsarbete. Avsätt till exempel en timme per vecka löpande för förbättringsarbete och planera också in större insatser regelbundet.
- Utgå slutligen (som alltid) från att det är ledarna som sätter föredömet. Chefer som alltid är perfekta och som inte kan identifiera, erkänna och bekräfta sina egna misstag är alltid dömda att ha fel beteende i sina organisationer. Vidare ska ledare inte ha alla svar. Däremot ska de ställa de rätta frågorna för att guida sin personal (vilket självklart görs på golvet, inte i chefsrummet). En ledare bör spendera minst halva tiden med produktionen och inte vara rädd för att sätta sig in i och förstå detaljerna.
Undvik flaskhalsar
Allt vi sagt hittills betyder att Utveckling (Dev) och Drift (Ops) måste börja arbeta tätt samman. Att då sätta en flaskhals emellan i termer av en specifik roll vars jobb det är att koordinera är inte rätt lösning. Visst, det är en god idé att ha någon resurs som hjälper Dev och Ops att finna varandra, men inte en roll som koordinerar. All form av koordinering är alltid slöseri (waste i Lean-termer) och bör undvikas eller helst elimineras helt.
Det är heller inte en roll vars uppgift det är att bara jobba med automatisering. Automatisering av tester, produktionssättning etc. är viktiga komponenter för att nå flöde, men i regel ligger inte våra stora flaskhalsar där utan istället hittar vi dem i resurser som inte finns på rätt plats vid rätt tid, driftspersonal som är dränkta i att hantera kapacitetsproblem eller incidenter som ett resultat av nyproducerad kod. En annan klassisk tidstjuv är utvecklare som får vänta på att driftspersonal blir tillgängliga för att utföra nödvändiga brandväggsöppningar, ompartitioneringar av resurser i virtuella miljöer eller liknande.
Att gå mot DevOps är alltså i första hand att mappa ut värdeflödet. Identifiera flaskhalsarna. Och utifrån det utveckla och förbättra organisationens förmåga att skapa “flow” i leveransen. Inte att anställa en person som ska skapa flow när resten av organisationen jobbar vidare precis dom de gjorde tidigare.
Snabbrörliga organisationers förmågor
Minimal overhead – i Lean-termer så skulle det översättas till eliminerat waste. Dvs att vi gjort oss av med allt som är onödigt, fokuserat endast på det som är värdeskapande för kund och löpande effektiviserat våra värdeskapande aktiviteter.
Oavbrutet genomflöde från krav till leverans – vilket är själva grundtanken med DevOps med stöd från systemtänkandet inom Lean. Dvs. vi har mappat värdeflödet att inkludera inte bara delmängder i silos utan hela värdekedjan från idé, till utveckling, till test, produktionssättning och sedan löpande fungerande stabil drift.
Begränsat eller inget person- eller funktionsberoende – dvs vi har identifierat och eliminerat flaskhalsarna i vårt flöde. Det här behöver naturligtvis inte bara vara i termer av personal utan kan även vara tekniskt. Men med hjälp av Lean-principen med korsfunktionella team som kan ta ansvar för hela leveransen (både utveckling och drift) så eliminerar vi många flaskhalsar.
Örat nära marken – eller snarare en tät, aktiv och förtroendefull dialog mellan kund och leverantör/IT-organisation. Med utgångspunkt från Leans närmast totala fokus på kundvärde och att hela tiden utmana huruvida de aktiviteter vi utför i vardagen tillför något värde för kunden. Skapas helt andra förutsättningar för att hela tiden kunna utveckla och leverera nya och bättre tjänster.
Snabb och effektiv problemlösning för att enkelt ställa om – vilket är kärnförmåga i en ständigt lärande och utvecklande organisation. Toyotas beskrivning av TPS (Toyota Production System
– upphovet till Lean) är att det i första hand är att vara en lärande organisation. Och i en lärande organisation så är problemlösning den viktigaste förmågan att ha hos personal.
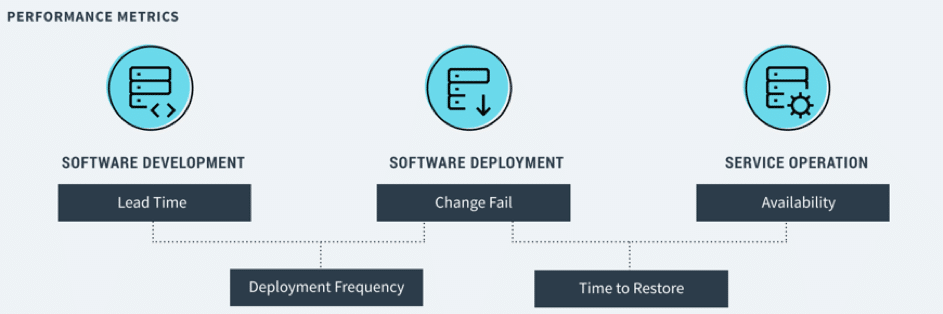
Rapporten State of DevOps från 2018 konstaterar att några av de minsta gemensamma nämnarna för framgångsrika IT-företag är att de har goda resultat på fem specifika mätvärden:
- Låg ledtid genom flödet
- Hög releasefrekvens
- Lågt antal fel när förändringar genomförs
- Kort tid för att återställa eventuella fel
- Hög tillgänglighet på systemen.
Det fina med just dessa fem värden är att de täcker in mycket av det DevOps representerar i termer av effektivitet, lättrörlighet och säkerhet.
(Image credit State of DevOps 2018)
Råd på vägen
För att undvika konflikter mellan drift och utveckling och förbättra samarbetet i totala leveranser till kund ger DevOps värdefulla råd i sina synsätt. Tillämpningen måste följa de specifika förutsättningarna för varje organisation och är ett arbete som pågår över tid. Samarbete, kommunikation och gemensamma mål kommer vara centrala komponenter under alla omständigheter.
Varje organisations tillämpning av DevOps kommer vara annorlunda, så fokusera på att utveckla era förmågor löpande och i små steg. För att göra detta måste ni se till att få in löpande återkoppling och strukturerade feed-back-loopar där alla berörda parter får göra sin/sina röster hörda. Vidare finns det gott stöd att få. Om inte i DevOps, så i de andra ramverken som DevOps förlitar sig på och bygger sina processer utifrån. Agile, Lean IT och ITIL är alla integrerade komponenter i detta. Men inte alla delar av dessa ramverk. Välj alltså ut de som passar för era behov.
Det finns ingen perfekt lösning, så det är bara att börja! Ta er tid till att lära och reflektera över framgångar och misstag i detta arbete och glöm dock aldrig bort varför vi gör detta; det handlar ju i slutändan om att se till att kundvärde realiseras.
Slutligen, bara för att vi gjort något på ett givet sätt historiskt så betyder det inte att det varken är rätt eller fel, det är bara historia. Nya utmaningar kräver nya lösningar så släpp loss er upptäckaranda i detta arbete!
Nästa steg?
Hur påbörjar man nu sitt arbete inom DevOps? I vilken ände och hur stort? På Onbird har vi gedigen erfarenhet av förändringsarbete, både i och utanför ramverken. Vi hjälper dig gärna, i vilken ända av DevOps-resan du än befinner dig. Vi ger dig dessutom gärna en intro-workshop, helt utan kostnad!

IT – en outnyttjad resurs i strävan efter affärsvärde
Detta är DevOps, en grundläggande sammanfattning av Martin Comstedt | mar 11, 2019 | DEVOPS Trots teknikens avgörande roll i affärsstrategier förblir IT och verksamheten ofta dåligt samordnade. Detta leder till att IT:s fulla potential som strategisk partner inte utnyttjas fullt ut. I många…

Vad hindrar flöde i våra IT-leveranser?
Detta är DevOps, en grundläggande sammanfattning av Martin Comstedt | mar 11, 2019 | DEVOPS Den osynliga bromsen – hur ineffektiva flöden kostar mer än du tror. Har du någonsin känt frustrationen över processer som borde gå smidigt men ändå fastnar? Du är inte…

Teknisk skuld - kostnaden som blockerar affärsmässig flexibilitet
Detta är DevOps, en grundläggande sammanfattning av Martin Comstedt | mar 11, 2019 | DEVOPS Teknisk skuld är inte bara en IT-fråga – det är en strategisk och ekonomisk risk som kan bromsa hela din verksamhets framgång. I en värld där digitalisering är avgörande…
